Cloud | Serverless
Understanding serverless cloud and clear 
Martijn van Dongen 29 Jan, 2017





Few industries have such unique challenges as the eCommerce sector, where companies need to meet the high volumes and demand on their digital solutions, while also meeting the high expectations of customers. Is it possible to build a service that meets all of this criteria, while still offering a viable, cost-efficient solution?
Perhaps one of the bigger issues for eCommerce is the high fluctuation in activity. Online shops have high traffic peaks during the day, but drop significantly at night. However, this can change completely during special sales and other active periods. Any online solution needs to adapt to these needs, yet maintaining your own servers for peak capacity results in a lot of downtime and unused resources that nonetheless cost money.
On top of this, users also need a satisfying, smooth experience. If customers are forced to wait when searching or filtering products, for example, they can get impatient and ultimately not complete their intended purchase.
With this in mind, our goal was simple. We wanted to check the industry’s current limitations and learn how viable it is to implement these common functionalities using Serverless services and DynamoDB in the Cloud. Any answer we produce also needed to be scalable – a crucial requirement for eCommerce solutions – so we decided on creating an application that will resemble a simple web shop, built via the Serverless approach and making use of all its advantages.
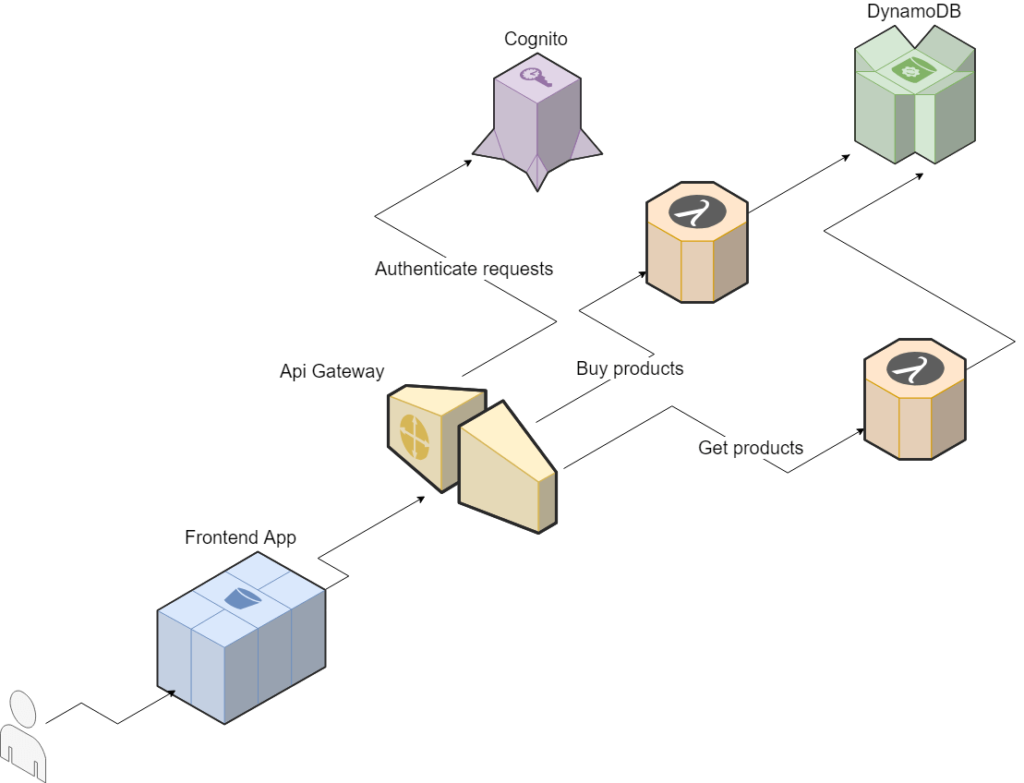
To meet these requirements, we chose to implement our application using Lambda and DynamoDB, which are fully managed services provided by AWS (Amazon Web Services), so integration between them was hassle free and enabled us to better focus on business logic and implementation.
AWS Lambda is a Function as a Service, which allows us to execute code without provisioning and managing servers. Our solution consisted of two Lambda functions; 1 to fetch products from the database and a 2nd to buy products. The latter, in essence, was responsible for making updates on the table with additional validation.
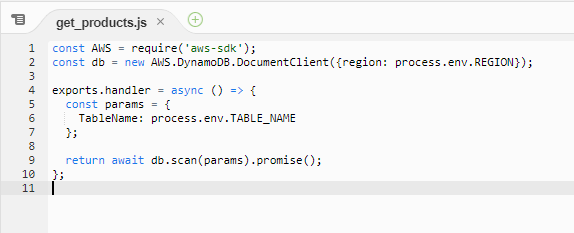
For the database service, we decided to use DynamoDB because it’s a fully managed service and provides seamless and fast scalability. Additionally, as it’s an AWS service, we could use AWS SDK for node.js in Lambda to communicate with it. Below, you can see how simple it is to implement such communication between Lambda and DynamoDB which, in our case, took just 10 lines of code.
Once the business logic of our application was ready, it needed to be exposed to the end-users. For this purpose, we decided to use another fully managed AWS service – API Gateway – which allows for the easy creating, publishing, and maintaining of APIs (Application Programming Interface). In a matter of minutes, we were able to create an endpoint that connects to our Lambda functions and exposes their functionalities, such as getting products.
API Gateway itself doesn’t resolve our security concerns, however, so we had to apply a mechanism to authenticate and authorise our users. To achieve this, we used AWS Cognito, which allows us to create an authentication mechanism that supports sign-ins with social identity providers, SAML and OAuth2. In our application, we implemented a simple sign-in function using our own user base, called User Pool, in Cognito and integrated it with API Gateway by creating an Authorizer and choosing it as Authorisation during endpoint configuration.
To allow communication with our backend, we also created a simple frontend application in Angular and hosted it using S3 bucket static website hosting. S3 is an object storage service that offers high scalability and availability, as well as security for the data we keep within. Additionally, S3 is really cost-efficient. For example, if we have 10,000 users, each making around 100 requests per day, it would only cost us around $1.
Using this, we then created an account that allows us to call our API:

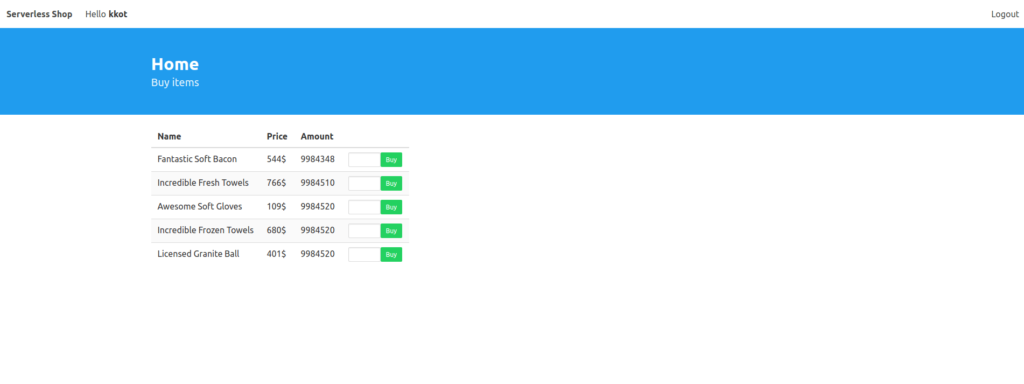
After this account was created, we were able to log in and view a screen with a list of products, all with the option to buy them. The only thing we have to do here is input the amount of products we want to purchase and click the “buy” button.
We decided to stick with Infrastructure as Code through the use of Terraform scripts. Thanks to this, we have full control over our environment on AWS and we are able to plan and review any changes we make. When using Lambda functions, there’s no real version control for any code we write but, thanks to keeping everything in Terraform, including function code, we have control over this as well.
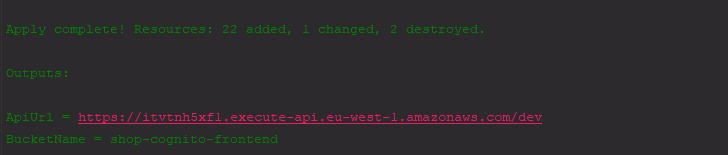
Furthermore, the whole deployment process is fully automated, so deploying the full infrastructure is a matter of just two or three commands. As a result, there’s no need to manually log in to the AWS console to update endpoints in API Gateway, for instance. Likewise, due to automation, even in a simple solution like ours, we are saving time and energy, alongside an increase in productivity.
On top of this, we also created a Bash script to build the frontend application with proper environment variables, such as URL to API, or the id of the Cognito user pool, and then deploy it to the S3 bucket.
As all the JavaScript code responsible for the functionality of our application resides in Lambda functions, it was really important for it to execute as quickly as possible. The main Lambda function used was the one responsible for buying products and additional work had to be done for this, which included validating if purchasing a specific item is even possible. Thankfully, we were able to keep this short, as the code needed took just 26 lines, while the function size itself didn’t exceed 500 bytes.
Another key factor to our success was having the Lambda function execute in a flash. This included when starting for the first time, in a so-called ‘cold start’. This fast started created a big impact on the function, lowering the required runtime and memory we needed to assign to it.
Likewise, it’s also important to note that, along with increasing memory usage, Lambda also proportionally increases the CPU power used. We made some test to determine the differences in execution time for different memory sizes:
| 128 MB | 1024 MB | 2048 MB | |
|---|---|---|---|
| Cold Start | 850-1100 ms | 100-120 ms | 80-110 ms |
| Next executions | 13-50 ms | 8-40 ms | 6-35 ms |
As you can see, with 128MB of memory, a cold start could last over 1 second, which was unacceptable for our needs, even though the next executions started within a satisfactory time. We were aiming for a cold start execution time of around 100ms, which was possible with 1024MB of assigned memory.
To test the performance of our API, we wrote a script in NodeJS, which sent a suitable amount of requests every second for a given period of time. This script was configured by a file uploaded on the S3 bucket and it contained, among other information, the chosen times to start these tests.
We decided to run this script from EC2 instance on AWS and, to achieve this, we used a tool called Packer to create and configure the AMI (Amazon Machine Images). After starting an instance from the created AMI, the testing script was automatically executed, so it downloaded the configuration file from S3 and waited to start sending requests. Because we wanted more than one of these instances, we also wrote a terraform script to launch a given amount of test instances.
During our first tests, we ran 10 t2.micro instances, each sending up to 2,000 requests per second, and we had a success rate varying between 90%-100% for each request. Unfortunately, these results were corrupted because we didn’t take the time in which responses came back into consideration, which sometimes took as long as 5 minutes. As it turned out, the instances we used were to slow to keep up with sending and receiving so many requests at the same time. After we discovered that the power and bandwidth of instances have a big impact on our tests, we decided to use more much stronger instances. From this moment on, we decided to run our tests on 100 c4.xlarge instances and, consequently, our tests represented the status of current sales much more realistically.
The following AWS settings were used in our tests:
| DynamoDB Capacity | Lambda Concurrency | Lambda Memory | Lambda Timeout |
|---|---|---|---|
| 10000 | 10000 | 1024 MB | 30s |
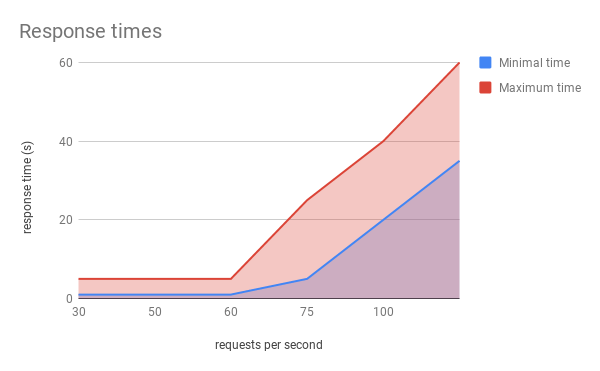
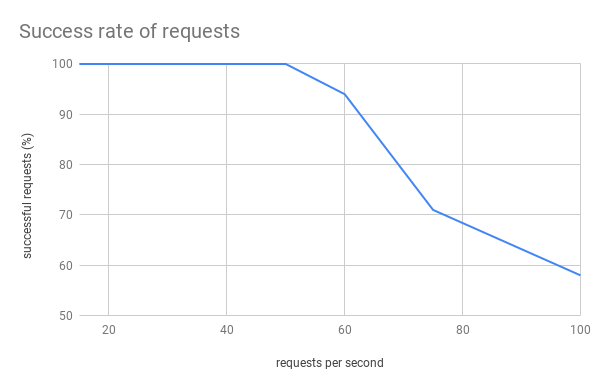
We started tests by sending 15 RPS (requests per second, which can roughly be translated to 15 people buying products simultaneously) from each of 100 instances and we incremented this value with each test, until we reached to 100 RPS. We were able to reach 50 RPS with a response time up to 3 seconds, resulting in 5,000 requests handled in real time, which was exactly our goal!
However, issues began to appear around 55-60 RPS, as the response time increased to as much as 20 seconds and the success rate of requests dropped to around 96%. With more requests per second, we noted more requests failed, while the response time also became longer. With 100 RPS, we had response times of up to 1 minute, with a successful request rate of around 55%.
The part of our solution which was limiting us was DynamoDB as, although the maximum write capacity we reached was about 4,700 units, the way in which DynamoDB resolves storing data in partitions caused our requests to be throttled. DynamoDB itself is capable of handling much higher traffic, but it would need some kind of optimisation of partition keys, such as splitting one item into many different keys, in which case partitioning would not be such a roadblock.
To more or less compare the costs of running our Serverless solution with an application running entirely on EC2 instances, we wrote a simple application in a NodeJS web framework, which is called Express. We quickly deployed this using Elastic Beanstalk.
In our estimations, we took into account cases such as Black Friday, so we calculated the costs of running a heavily loaded app for 24 hours. As our Serverless project was able to handle 5,000 RPS, we calculated EC2 costs for the same loads.
A Lambda-based solution for 432 million requests (5,000 RPS) would cost us around $800.
Our Elastic Beanstalk app was originally created with 2 m4.4xlarge instances behind a Load Balancer, handling 150 RPS between them. With each instance handling 75 RPS, to achieve results that mirrored our Serverless project (5,000 RPS), we needed 67 instances.
So, with 67 instances operating at $0.888 per hour, across 24 hours, the total cost per day would be $1,427.
Of course, our calculations were made for applications with a constant load across a full 24 hour period, which is not a very realistic case at all, but it serves to illustrate the difference in potential costs.
First of all, we learned how many requests per second our application is able to handle in real time, which was 5,000, and that we are well on our way to reach even more, once we resolve partitioning in DynamoDB. One way to achieve this could be increasing the write capacity in our database and dividing products in such a way that one product has records on multiple partitions.
Furthermore, another additional lesson we learned from this was exactly just how scalable Lambda functions are. Basically, Lambda is able to immediately provision 3,000 concurrency, but then it’s scaled out at a rate of 500 additional concurrency per minute, up to our limit (the default is 1,000).
We have also discovered how fast and pleasant the implementation of Serverless solutions can be. Thanks to using readily available AWS services, we aren’t forced to reinvent the wheel regarding the likes of authentication – instead, we resolved this using Cognito. Instead, we can just focus on the business logic of our application, rather than worrying about implementing things such as autoscaling.
To surmise, our API handled 5,000 RPS in real time, which is great result! This gives us fast, out of the box scalability, yet we will only ever pay for the resources we need at any given moment, while still having access to more computing power and processing as and when required.
The eCommerce sector faces numerous tough challenges but, by moving to a Serverless solution, businesses can achieve an affordable solution that will rapidly scale up and down with demand, removing wasted resources and expenditure during down times, while ensuring you’re able to handle larger peak volumes whenever they occur.



