Software Development
Auto-Scaling on Alibaba Cloud 
Léon Rodenburg 01 Apr, 2019





Amazon Web Services (AWS) offer numerous solutions – this gives us, as developers, a broad range of optional tools to meet a client’s business objectives, but how do we determine the best solution?
This is a situation that we’re always thinking about, so we’re always looking to test possible solutions, even at a hypothetical stage or when building proof of concepts (PoC) that can be developed further. In this instance, we wanted to explore scaling containerised applications. So, armed with a potential real-world scenario in mind, I set to work to test the two most viable options, to see which met the required business objectives.
Let’s imagine that a photography company desires to extend its portfolio with photo editing services. The company’s clients around the globe will upload a large number of pictures to process and the business has assumed, based on prior data to date, that there won’t be more than 10 thousand of images to process during any 30 minute period. This should be treated as the edge case that the system would experience.
The photography company would like to have infrastructure that is able to work effectively when there is a massive amount of uploads, yet also wants to not overpay for infrastructure at night, when there is not much images to transform. They also want to quickly implement this new solution and reduce the time to market. The company has also heard about Cloud solutions and would like to use these features. After images have been edited, both the original and transformed version should be downloadable, as long as users don’t delete them from the service itself.
The first solution that comes to mind is serverless computing, using AWS Lambda, but the organisation is not ready for such innovation. For purposes of transformation, they have already built three containerised applications to process large numbers of images:

Figure 1 An image before and after conversion to grayscale

Figure 2. An original image and a thumbnail
Our main goal was to build a Cloud infrastructure that meets the following business requirements:
Keeping these business objectives in mind, we decided on implementing a Cloud architecture that comprises Amazon S3 as an object storage service, and Amazon SQS as a queuing service. These services were obvious candidates, as will be explained below. However, we decided to test Amazon container services to run and scale these image processing applications and compare their features. The AWS architecture diagram below visualises all the resources provisioned within a Virtual Private Cloud (VPC), along with their relationships.

As shown in the diagram above, when any image file is uploaded to the specified folder in the S3 bucket, the S3 event notification is sent to the appropriate SQS queue. For instance, as soon as the s3:ObjectCreated event occurs in the input/grayscale folder, the link of the recently uploaded image is sent to a dedicated queue. Following this, the application, which runs on one of the discussed Amazon container management services, retrieves the picture address from the queue, downloads it from the S3 bucket and converts it into the grayscale intensity. The processed image is sent to the output/grayscale folder in the origin S3 bucket.
The assumption that the massive number of images all need to be processed led us to choose Amazon S3 as object storage solution. Amazon Simple Storage Service offers an extremely durable (99.999999999% durability of objects) and highly available data storage infrastructure with low latency and high throughput performance. Moreover, event notifications to Amazon Simple Notification Service (SNS), Amazon Simple Queue Service (SQS) or AWS Lambda can be sent in response to changes in the S3 bucket. As the images must be transferred to containerised applications once they are uploaded to the S3 bucket, the Amazon S3 notification feature, along with Amazon SQS, was a great choice.
Amazon SQS is a cost-efficient message queuing service that facilitates the decoupling and scaling of distributed software components. Copies of every message are stored redundantly across multiple availability zones. SQS can transmit any volume of data without requiring other services to be always available, which is cost effective. Furthermore, standard SQS queues offer at-least-once delivery, which meets the requirement to process the image once, as well as helping to reduce costs.
AWS offers multiple container products to deploy, manage and scale containers in production. In the AWS Cloud, containers can be run using Kubernetes with Amazon EKS, Amazon Elastic Container Service (ECS), and AWS Fargate. We deployed the image processing applications to these container orchestration services and implemented auto scaling, in order to compare container performance, operational efficiency, and cost.
Amazon ECS allows us to easily run, manage, and scale Docker containers on a cluster within a VPC, a logically isolated section of the AWS Cloud with network traffic control. The Amazon ECS cluster is a regional grouping of services, tasks, and container instances, if the EC2 launch type is used. When a cluster is up and running, task definitions must be defined created. The task definition is a JSON file, which describes one or more containers, with parameters such as Docker images to run, ports to open for the application or data volumes to use with the containers.
Additionally, container images for the grayscale, thumbnail, and watermark applications were stored in and pulled from Amazon Elastic Container Registry (ECR). Amazon ECR helps to securely store, retrieve, and deploy Docker container images. In our case, the cluster included three ECS services, each for one of the applications. The service was responsible for launching and maintaining a specified number of instances of a task definition, also called tasks, simultaneously in a cluster. Whenever any tasks stopped, the ECS service scheduler launched another instance of the task definition.
Furthermore, the service was run behind an elastic load balancer (ELB) to distribute traffic evenly across the tasks, which helps to achieve greater levels of fault tolerance.
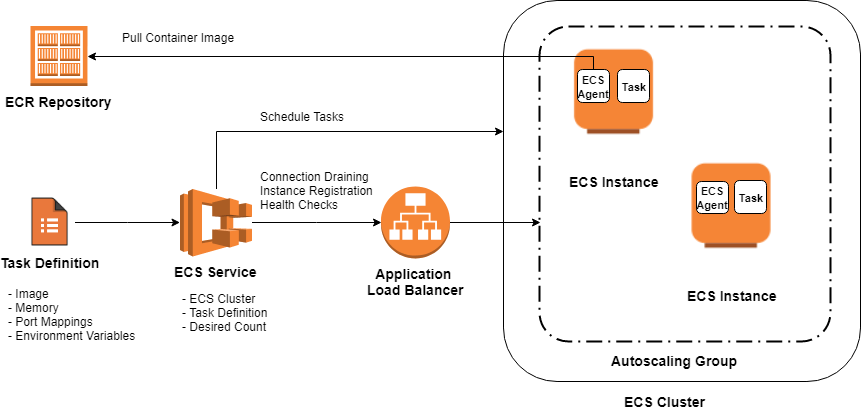
For the Amazon ECS cluster, an Auto Scaling group was created, which included container instances that could be scaled up and down using CloudWatch alarms. The Auto Scaling group used two custom scaling policies:
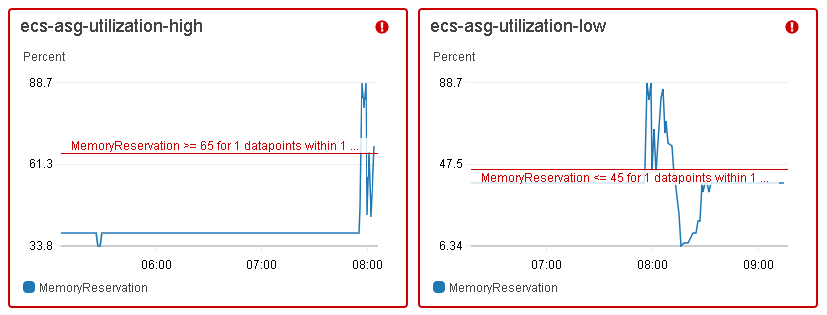
As shown in the preceding CloudWatch graphs, the ecs-asg-utilization-high alarm triggered the scaling policy when the ECS cluster’s memory reservation went beyond 65% for 60 seconds, whereas the ecs-asg-utilization-low alarm executed the scaling policy when memory reservation was less than or equal to 45% in a 1-minute sliding window. Using a lower threshold than the scaling up one affords us a cool-down period, so there will not be any resource struggle when shutting down instances.
CloudWatch alarms invoke actions only when the state changes and it is maintained for a specified period. For instance, when any data point collected in a time window does not exceed the configured threshold, the CloudWatch alarm is not triggered. Similar, the alarm is set back to normal when at least one of the periods is not breaching the threshold.
For each Amazon ECS service, auto scaling was configured to adjust a desired tasks count up or down, in response to CloudWatch alarms. Based on the number of messages available for retrieval from the SQS queue, tasks were added or removed from the ECS service. The graphs below show a change in the number of messages ready to process in the grayscale service.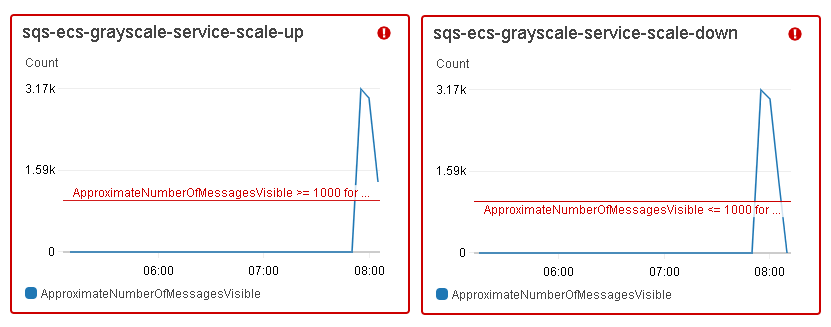
The sqs-ecs-grayscale-service-scale-up alarm triggered the scaling policy to add 5 tasks when the ApproximateNumberOfMessagesVisible was greater than, or equal to, 1,000, as well as add 10 tasks when this number went beyond 3,000, whereas the sqs-ecs-grayscale-service-scale-down alarm executed the scaling policy to remove 5 tasks when the number of messages on the SQS queue was lower than, or equal, to 1,000.
In order to test the ECS cluster auto scaling, as described above, 10,000 images were uploaded to the input folders in the empty S3 bucket: grayscale, thumbnail and watermark, accordingly. Then, the following test cases were executed:
The table below presents the test results, including the duration of the image processing, the duration of tasks scaling up in each ECS service, and the duration for ECS container instances scaling up.
.tg {border-collapse:collapse;border-spacing:0;border-color:#aaa;}.tg td{font-family:Arial, sans-serif;font-size:14px;padding:10px 5px;border-style:solid;border-width:1px;overflow:hidden;word-break:normal;border-color:#aaa;color:#333;background-color:#fff;}.tg th{font-family:Arial, sans-serif;font-size:14px;font-weight:normal;padding:10px 5px;border-style:solid;border-width:1px;overflow:hidden;word-break:normal;border-color:#aaa;color:#fff;background-color:#f38630;}.tg .tg-g2j5{font-size:16px;background-color:#ffffff;color:#333333;border-color:#000000;text-align:center;vertical-align:top}.tg .tg-gtua{font-weight:bold;font-size:12px;background-color:#ffffff;color:#333333;border-color:#000000;text-align:left;vertical-align:top}.tg .tg-7btt{font-weight:bold;border-color:inherit;text-align:center;vertical-align:top}.tg .tg-0pky{border-color:inherit;text-align:left;vertical-align:top}
| Test Case | Duration (seconds) | ||||
| Image processing | Greyscale Tasks scaling up | Thumbnail tasks scaling up | Watermark tasks scaling up | ECS instances scaling up | |
| 1 | 861 | – | – | 720 | 840 |
| 2 | 940 | 800 | 840 | 642 | 782 |
| 3 | 978 | 500 | 260 | – | 820 |
| 4 | 1022 | 660 | 541 | 901 | 719 |
As shown in the table, a change in the CloudWatch threshold had a noticeable impact on test results. We expected that, after a decrease in the alarm threshold, the time taken for tasks scaling up and image processing would be lower than with the larger threshold. Comparing cases 2 and 4, where the threshold for test case 2 is 4 times bigger, the time for tasks scaling up has dropped for grayscale (from 800 seconds to 660 seconds), as well as for thumbnail (from 840 seconds to 541 seconds) images. In the case of watermarks, the scaling took longer (time increased from 640 seconds to 901 seconds). Probably, this outlier value results from the fact that, at the beginning of test case 4, there were tasks from grayscale and thumbnail folders, but the watermark appeared on the second EC2 instance, so the time for scaling up was longer. It would be a good idea to change a simple scaling policy to a scaling policy with steps, where you can set several scaling steps, depending on the memory reservation.
It is also worth remembering that, in such a situation, performing tests is very important to find the optimal scaling solution. After all, it’s through these tests that we are able to determine these recommendations going forward.

Figure 4 Example of step scaling in Auto Scaling Group
The charts below show the evolution of SQS messages count and tasks count against time for test case 1 and 2.
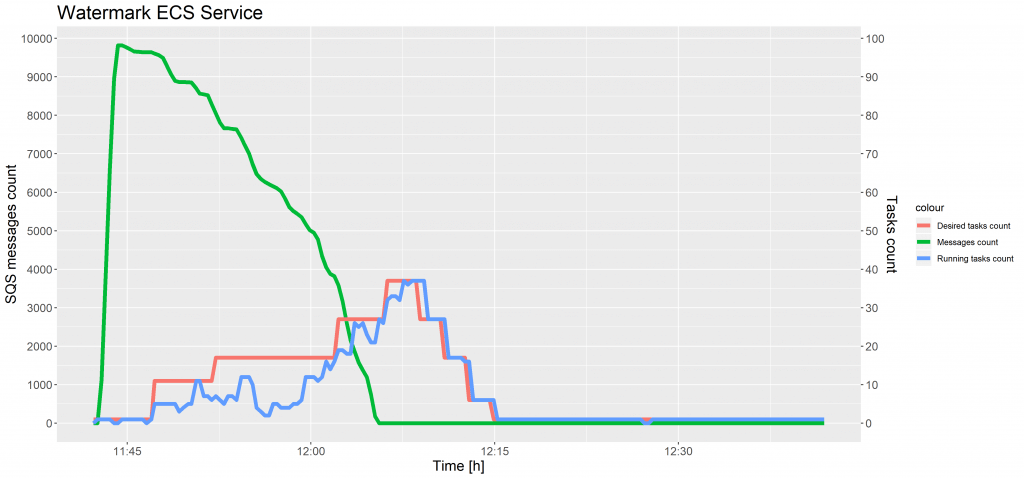
In the chart above, between 11:40 and 11: 55, the number of running tasks had decreased several times. When the memory in the cluster was not sufficient to reserve new tasks, another container instance was added, while some tasks were terminated and placed on the new host to allocate resources more effectively.
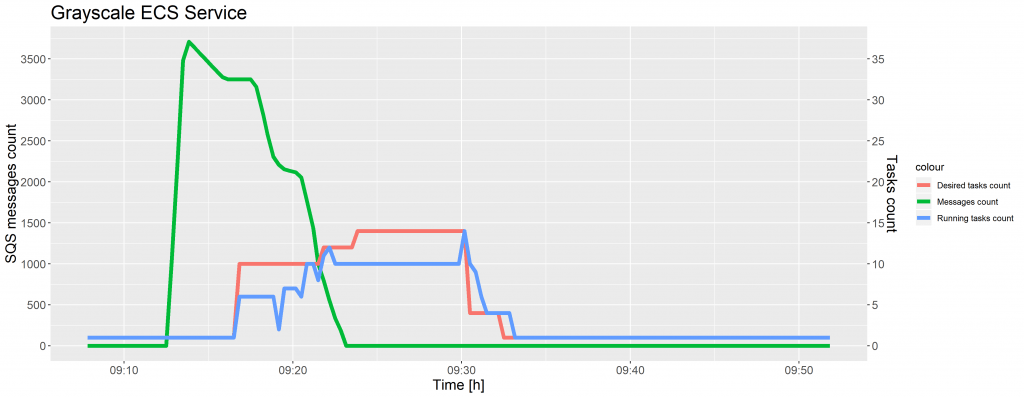
As shown in the preceding charts, the desired tasks count was not increased immediately after the SQS messages count was equal to the threshold, but with a time delay. The reason for this is that metrics for Amazon SQS queues are collected and pushed to CloudWatch every five minutes. A possible solution to this problem is writing an AWS Lambda function to monitor SQS queues more often and control tasks scaling in the ECS service. However, we decided to use an off the shelf solution, as provided by AWS.
When the percentage of memory reserved by running tasks in the cluster rose above 65, the CloudWatch alarm triggered the Auto Scaling group to add another instance. When the cluster memory reservation was less than 45%, the CloudWatch alarm executed the Auto Scaling group policy to remove container instances. The figure below presents a change of cluster memory reservation and ECS instances counts over time, when the images were uploaded to the grayscale, thumbnail and watermark folder, once again in the proportion of 40:40:20.
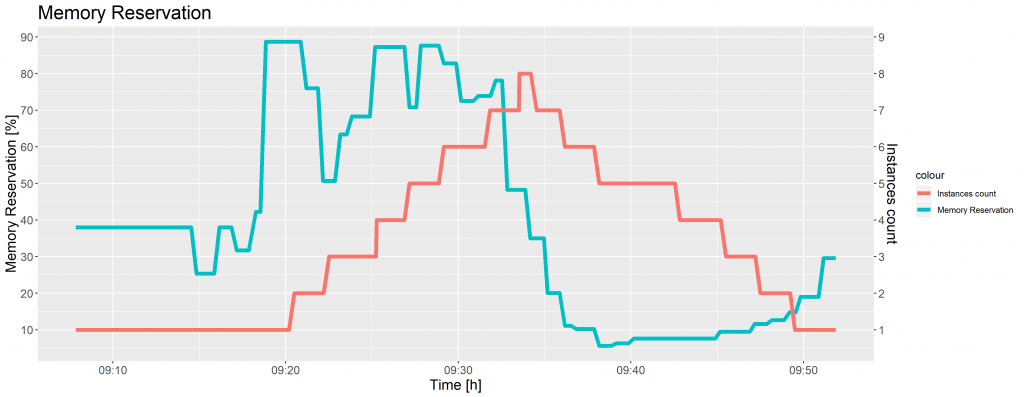
Figure 3 shows the EC2 instances were added immediately after the CloudWatch alarm threshold was exceeded. The Auto Scaling group terminated 7 instances in 15 minutes, which is the standard termination time of the EC2 instances.
Using Amazon Elastic Container Service with the EC2 launch type, you pay for AWS resources, mainly for EC2 instances created to run containerised applications. There are no minimum fees and no upfront commitments. In the EU (Ireland) AWS Region, where these ECS tests were conducted, the price per On Demand Linux t2.medium instance per hour is $0.05, and the price for the Application Load Balancer per hour is $0.0252. Thus, in the case of 8 instances running with the aim to process 10,000 images, the total compute charges were equal to:
Total compute charges = 8 × $0.05+ $0.0252 = $0.4252
AWS Fargate is a compute engine for Amazon ECS that runs containers without requiring to select Amazon EC2 instance types, provision, and scale clusters, or patch each server. When tasks and services with the Fargate launch type were run, applications were launched in Docker containers, and the CPU and memory requirements were specified within Fargate’s tasks definition. Even though there are no instances to manage with Fargate, tasks are grouped into logical clusters.
Similar to Amazon ECS, each Fargate service had auto scaling configured to maintain the desired count of tasks. The CloudWatch alarms were created to add and remove tasks when a number of messages in the SQS queue changed. As Fargate manages the underlying infrastructure, container instances scaling was not applied. Analogously to ECS, 10,000 images were uploaded to the input folders in the S3 bucket: grayscale, thumbnail and watermark, accordingly. The following test cases were executed:
The table below presents the test results, including a duration of the image processing and tasks scaling up in each Fargate service.
.tg {border-collapse:collapse;border-spacing:0;border-color:#aaa;}.tg td{font-family:Arial, sans-serif;font-size:14px;padding:10px 5px;border-style:solid;border-width:1px;overflow:hidden;word-break:normal;border-color:#aaa;color:#333;background-color:#fff;}.tg th{font-family:Arial, sans-serif;font-size:14px;font-weight:normal;padding:10px 5px;border-style:solid;border-width:1px;overflow:hidden;word-break:normal;border-color:#aaa;color:#fff;background-color:#f38630;}.tg .tg-g2j5{font-size:16px;background-color:#ffffff;color:#333333;border-color:#000000;text-align:center;vertical-align:top}.tg .tg-gtua{font-weight:bold;font-size:12px;background-color:#ffffff;color:#333333;border-color:#000000;text-align:left;vertical-align:top}.tg .tg-7btt{font-weight:bold;border-color:inherit;text-align:center;vertical-align:top}.tg .tg-0pky{border-color:inherit;text-align:left;vertical-align:top}
| Test Case | Duration (seconds) | |||
|---|---|---|---|---|
| Image processing | Greyscale Tasks scaling up | Thumbnail tasks scaling up | Watermark tasks scaling up | |
| 1 | 739 | – | – | 560 |
| 2 | 800 | 500 | 500 | 220 |
| 3 | 800 | 439 | 360 | – |
| 4 | 601 | 518 | 536 | 575 |
As shown in the preceding table, images were processed faster in comparison to Amazon ECS, because AWS Fargate managed all the scaling and infrastructure needed to run containers in a highly-available manner.
The charts below show the evolution of the SQS messages count and the tasks count against time for test case 1 and 2.
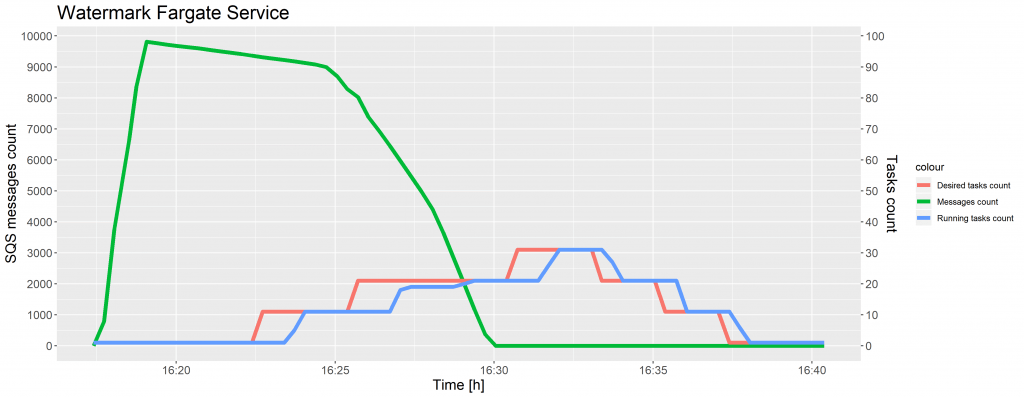
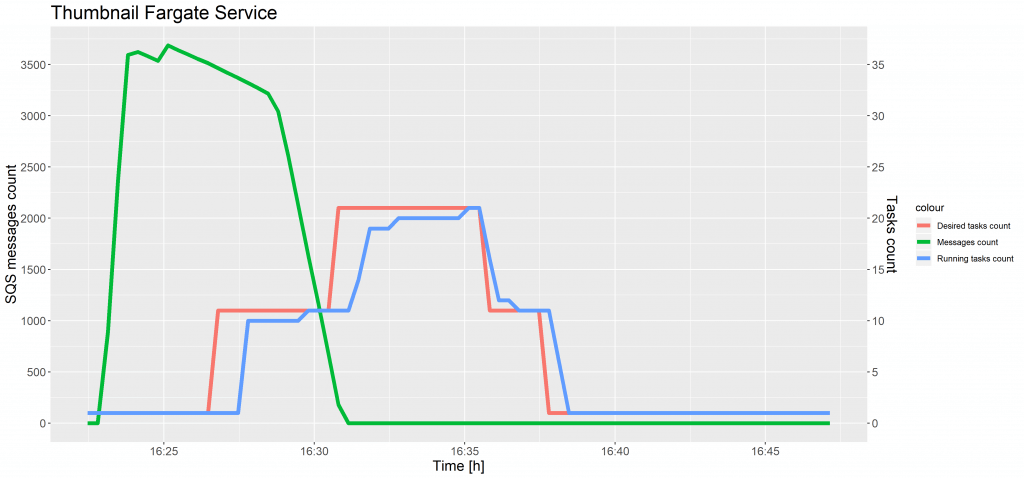
As shown in the preceding charts, a time delay occurred in increasing the desired tasks count after the CloudWatch alarm reached the threshold. This same situation took place while scaling ECS tasks and was caused by the 5-minute interval on SQS metrics. The instances of a task definition were scaled seamlessly, without decreasing a number of running tasks.
AWS Fargate has resource-based pricing and per second billing, which means that you only pay for the time for which resources are consumed by the task. The price for the amount of vCPU and memory resources are charged on a per-second basis. The duration is calculated from the time downloading container images starts, until the task terminates. Our Fargate services were running in the EU (Ireland) AWS Region, where a price per vCPU per hour is $0.0506, and a price per GB of memory per hour is $0.0127. Total vCPU charges should be calculated using the following formula:
vCPU charges = # of Tasks × # vCPUs × price per CPU per second × CPU duration per seconds
Total memory charges should be calculated using the following formula:
Memory charges = # of Tasks × memory in GB × price per GB × memory duration per seconds
For example, when 90 tasks were running for 12 minutes (720 seconds) to process 10,000 images, and each task used 0.5 vCPU and 0.5 GB memory, the vCPU and memory price were equal to:
vCPU charges = 90 × 0.5 × 0.00001406 × 720 = $0.455544
Memory charges = 90 × 0.5 × 0.00000353 × 720 = $0.114372
Hence, the total Fargate compute charges were equal to $0.569916 in this discussed case.
AWS Fargate offloads responsibility for the underlying Amazon EC2 instances. On the other hand, managing EC2 instances gives more control of server clusters and provides a broader range of customisation options. Access to these container instances can be useful for some purpose, like installing advanced software or debugging. Amazon ECS with the EC2 launch type turned out to be a cheaper container orchestration service than AWS Fargate. Images were processed slower, but the total compute charges were lower, so the business goal to run containers at the lowest possible price was achieved.
However, this solution would require even more administrative effort to optimise the auto scaling and get better results – for instance, by using step scaling with appropriate thresholds.
Using AWS Fargate, configuring the infrastructure and launching tasks is simple, and we no longer have to worry about provisioning enough compute resources for the container applications. Moreover, the images were processed faster in the tasks with the Fargate launch type (10,000 files in approximately 12 minutes) than with the ECS launch type (10,000 files in about 16 minutes), because the Fargate tasks were not terminated and relocated on the new EC2 instance. This meets the business objective to process 10 thousand photos in less than 30 minutes.
For the hypothetical photography company behind this scenario, the most important aspect is the time to market and eliminating the administrative overhead, so the best option is to use AWS Fargate. If changes in the architecture of the application would come into play, however, we would recommend using AWS Serverless with AWS Lambda.
As a PoC, this experiment has proven the different merits behind different AWS tools, which can be chosen to suit the most important business needs. Moving forward, both options could be developed further and supported with additional instances. Likewise, the underlying technology here isn’t limited just to image processing, as it could also be used publishing digital content, handling business orders (as well as their subsequent delivery), audio transcriptions, plagiarism analysis and more. All of these examples can use the underlying framework built here.
With the Cloud and AWS technology, there’s more than one way to achieve any goal. However, each method has its own particular strengths, so designing a solution that meets the most important business objectives, whether it’s time to market or long term overhead costs, can influence the final decision. Nonetheless, effective testing of these solutions enables us to make the best recommendations for each and every client.


