Java | Testing
How to Fail at Writing Bad Code 
Age Mooij 03 Feb, 2011





Machine Learning has a variety of uses. There are numerous problems Machine Learning can solve, for businesses large and small. Yet, while Machine Learning is used for countless tasks, it’s not a simple solution. It takes plenty of training and data, so developers should be as familiar with the technology as they can be – even if that means making prototypes and Proof of Concepts (PoCs) for board games!
Impressed by DeepMind’s AlphaZero achievement with game of Go, we tried to use a similar approach to implement AI for the highly acclaimed board game, Azul. We discovered that reinforcement learning is not a necessary ingredient of successful solution – and we also learned that using your favourite tools can sometimes lead you astray.
Chapter 1: Where Everything Goes Well
In March of 2016, the world learned that an algorithm designed by DeepMind won a Go tournament (a historic game from China) against Korean grandmaster Lee Sedol. The Machine Learning community was shocked, as Go is considered to be the hardest board games to implement a computer player for, due to the astronomic number of possible game states and very large branching ratio on every move.
DeepMind’s historic achievement was a result of both the innovative neural network architecture and compute power investment, worth million of dollars. The algorithm in question was later generalised to work with more board games (such as chess and shogi) and – what’s even more astounding – reworked to start learning with zero expert knowledge, tabula rasa, only able to recognise what the possible moves are for the given board state.
We were inspired by both the simplicity and smartness of DeepMind’s approach and decided to prepare our own computer player, able to play a board game. Specifically, we wanted to implement a set of rules, but not include any expert knowledge of successful strategies or tactics.

Azul is a very popular board game, ranked on BoardGameGeek (at the moment of writing) as #1 in both “Abstract” and “Family” categories – which do not overlap very often. It also won the prestigious “Spiel des Jahres” (game of the year) award in 2018, among many others.
The rules are fairly simple – players compete to arrange patterns of colourful tiles, drawing resources from a common stock. Points come from aligning tiles in rows and columns, with bonuses for a full row, full column and completed tile colour set. You can learn more about the rules and gameplay here.
What matters to us, however, is that Azul meets some important game theory criterias, including:
Unlike Go or checkers, where a single game results with a win of one side (or a draw), in Azul, success level can be also measured as a number of points scored by player. In a somewhat simplified approach, we can measure agent quality as the average number of points in self-play, instead of counting the win ratio against an opponent.
This approach also enables us to do additional simplification – we can completely skip the “offensive rivalry” problem and only optimise against our own score. Our agent will only look at the common board area and its own sub-board, ignoring the position of the adversary’s sub-board. We can tell from experience that, in Azul, one can usually disturb the other player’s plans by making a sub-optimal move that hurts others more than ourselves. In general, it’s hard to evaluate the level of aggression and competitiveness of a computer player, so we skipped this problem completely.
In board games, you can often predict the future by guessing the opponents answers to your moves, then invent your counter actions, guess their counter-counter actions and so on. In computer science, this approach is known as a tree search problem (a term coined from graph theory). In this case, each tree node represents a game state and each edge connecting nodes represents a single move. In many games, the number of possible moves grows way too fast, preventing even the largest of super-computers from going through the complete tree and selecting the optimal move.
Since the dawn of computer science, algorithms like “minimax” and “alpha-beta pruning” were used to detect and skip calculations that, for sure, won’t improve a player’s score. However, such savings were way too small to truly improve a computer’s predictive power, so modern approaches prefer randomised heuristics over deterministic algorithms. Heuristics won’t always provide an optimal solution but, in practice, they enable us to deal with challenges that lie beyond the reach of traditional algorithms such as minimax.
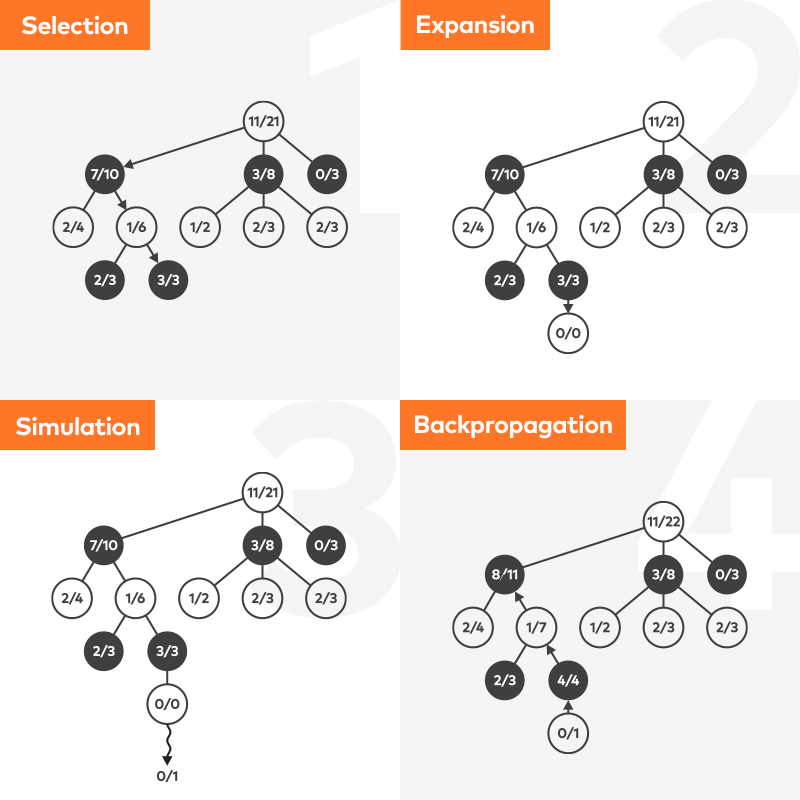
In our approach, we used the Monte Carlo Tree Search (MCTS) which – as the name suggests – employs randomness to “guesstimate” the value of given moves. We won’t describe the algorithm in full, as there are many excellent articles and video tutorials covering this topic already. It is only important to know that MCTS continuously simulates possible game rollouts from a given state and, after each iteration, updates the estimated value of examined moves. A simulation loop can be interrupted either after an assumed number of iterations or after a specified period of time has passed.
Most computer implementations of board games are very similar. We can distinguish a class holding the current game state, which usually means keeping records of game pieces and their specific positions or presence, as well as absence of cards, tiles, active bonuses and so on. Other classes represent single game moves and AI agents, as well. There is also an arena, which updates the game state and supervises agents, allowing them to do moves alternatively and making sure no agent is able to cheat (i.e. by making forbidden or impossible moves).
We decided to implement our solution in .Net Core, partially due to personal preferences for the C# language and Microsoft ecosystem, but also because of easiness of portability to Linux. Being more specific, no port needed to be done at all, as the very same C# code ran on Windows and Linux – but more on that later!
The first agent was the “manual” one, where a human was making the moves – this was used to identify and clear all rule engine bugs and faulty edge cases. Then, we went with the MCTS agent, that… played like total noob, rarely rising above zero points. Azul really doesn’t forgive stupid moves and penalty points are severe. A subsequent debug session revealed that we made the mistake of allowing MCTS unroll stage to play until the game was over, which went through a couple of random tile restocks – so every MCTS iteration played a different game. No wonder the results did not converge to anything meaningful!
The solution to the above problem was to limit the prediction horizon to the end of the current stage, which means the agent won’t do any long-term planning, but will focus only on the goal that is reachable, here and now. Of course, it’s possible to artificially add a long-term strategy with fake goals and bonuses, such as by granting some void score for 3 or 4 tiles in one colour, whereas game rules only grant a bonus for 5-tile set. We decided to skip this option and instead check what the average score is, without any assistance from human experts.
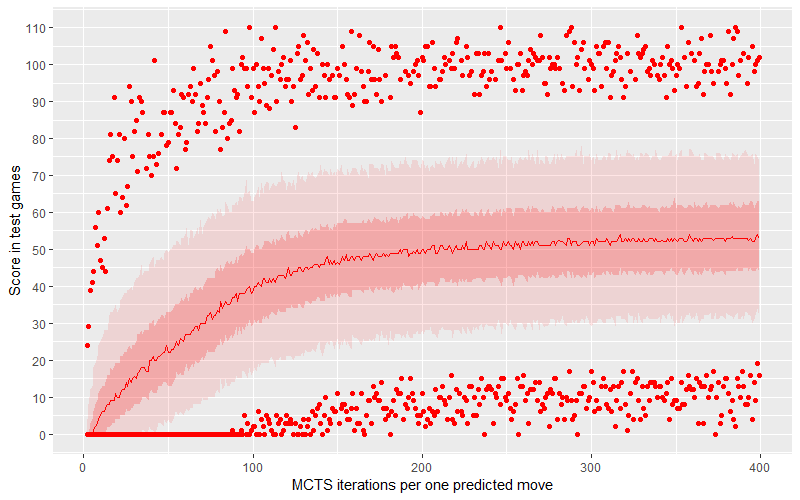
It turned out the MCTS agent is really good. We treated the MCTS loop number as a metaparameter and checked the results, with a range of 2 to 400 iterations and simulating 1,000 games for each value. On the graph above, we can see the relation between loop number and average score. The dark ribbon is the middle half of the points (2nd and 3rd quartile), while the light ribbon is the middle 90% of points (dropping 5% from top and bottom – these are outliers).
It turned out that both the mean and average scores exceed 50 points in an average game when the number of MCTS loops (per single predicted move) is bigger than 225. What’s also important here is that the minimal score for simulated games is rising above zero even earlier… however, we have to remember that Azul’s random rewards and punishments can be severe and extreme scores don’t really tell us as much about the algorithm’s strength than it might seem at first.
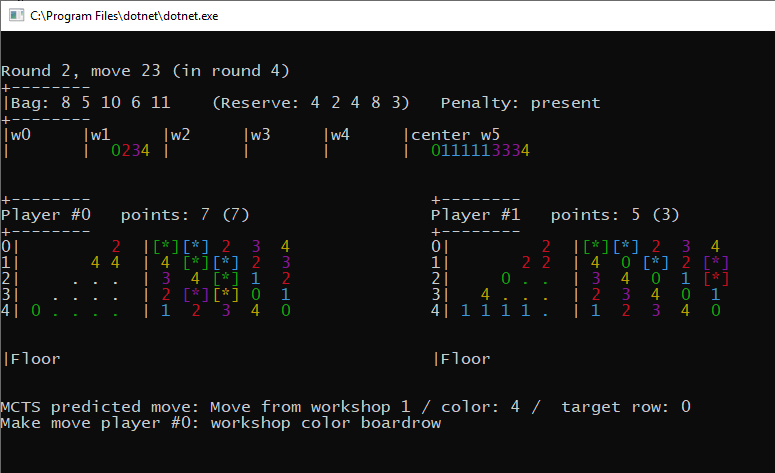
Performance also met expectations as, with 300 iterations per move, we were able to simulate a full game in 0.5 seconds on a single CPU core, which parallelised nicely to over 10,000 games per hour on a typical developer workstation (i5 8500, 6 cores, for those who are curious).
Of course, we did test plays against our agent and we have to say its moves just make sense. The difference between playing with a human can also be visible – fellow players typically value a higher score and more bonus achievements above a quick finish. The agent did otherwise; it ended the game as soon as possible because of a small row bonus (also a game end condition), unaware of more valuable incentives available in the next round.
Chapter 2: Where We Hit Some Problems
Since the beginning of this research, we intended to try the “magic” approach to Machine Learning. You know, everyone can understand how the tree search works, whereas it is hard to understand neural networks as a concept and even harder to understand how a given problem is internally represented in a trained network. So, a neural network playing Azul would surely be something a little bit mysterious.
If you follow or engage in the Machine Learning community, you surely noticed the unusual popularity of the Python programming language. It’s a very universal tool and many people without a computer science background are able to quickly pick up the basics, start prototyping basic code, solving their problem and reaching for 3rd party libraries as their skills are growing. But if you have already decades of experience with .NET, Java and R, Python has much less to offer – especially given the most popular ML libraries like Keras have wrappers and interfaces to other languages.
We decided to leverage our knowledge of R language, which is popular among many data scientist, and use the existing, mature Keras bindings, which are available in the R environment. By choosing Tensorflow as a low-level backend for Keras, we were hoping to use the power of the GPU on both Windows and Linux machines. R itself would be embedded in our C# implementation, using a R.NET interop library. Experienced software developers can already see a chain of dependencies here: C# is calling the interop library, which is calling R code, which is calling the Keras wrapper, which is calling Python code, which is calling Tensorflow code, which is calling the CUDA library, which is – finally – executing calculations on the GPU.
R&D projects have a short lifespan, so we decided to go with such a heavy dependencies set, having full awareness of its fragility. We developed a quick series of Proof of Concepts for each stage and it all just worked, thankfully. But, kids, I have to warn you! Do not try it in production environments! It will work for some time but can break easily after any random update of any component. You have been warned.
The first issue we hit was the R.NET single-threading model. It’s not a deal-breaker, but having MCTS agents running in parallel threads at full speed was nice and, in this case, we would need to implement inter-process locks, taking an inevitable performance hit.
The second issue was the R.NET library’s compatibility with language runtime. As development of this library slowed significantly in 2017, the most recent release available (at the time of writing) was not compatible with the R runtime version 3.5, released in 2018. Old R releases are still available, but it will get harder to have them running as time passes by. That being said, we went with R 3.4.4.
Finally, the third unexpected issue hit us hardest, as we didn’t catch it during the initial PoC phase. The R.NET library is able to invoke R calls a 30,000 times per second. However, it turns out that, when we add marshalling hundreds of input and output parameters to R code invocation, after some time the main process terminates throwing System.StackOverflowException.
Much to our initial surprise, this happened on both Windows and Linux. As far as we understood the comments in github bugtracker, R is not able to cope with the garbage collection of large number of unnamed objects created by R.NET bridge. What’s worse, the issue was first manifested in 2015 and looked like a real deal breaker – we tried throttling, manual GC invocations on both R and C# sides, manually tune stack size… but nothing worked. The least we could do was to provide a reproducible bug report and hope for the best. After a few weeks, it’s now been acknowledged, but neither fixed nor scheduled for a fix.
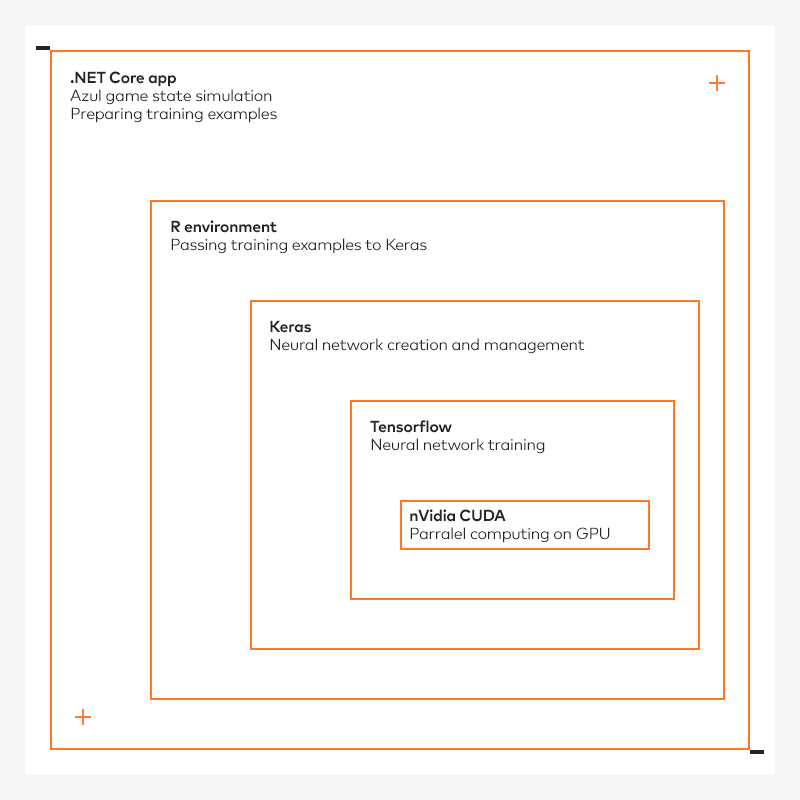
Consequently, we produced a workaround, which introduced even more dependencies. As the problem only manifested when we reached thousands of prediction invocations, we decided to still use embedded R with Keras to train the NN model, but later export the trained weights to file, convert it to raw Tensorflow protobuf format using some explicit Python code (a new dependency!), load it into a TensorFlowSharp component (another new dependency!) and continue with prediction inference going through this new component – fortunately more stable than R.NET.
Again, all the setup described above is very fragile. TensorFlow and TensorFlowSharp depend on the NVidia CUDA version, Keras depends on the Tensorflow version, R.NET depends on the R version and, better still, half of the above depend on the Python version (or vice-versa). It is expected that one component lagging behind will force you to freeze whole versions of the setup and any unpatched security issues will haunt you forever more.
You may prefer C# or Java, but if your toolset does not directly support bindings to those languages, you are risking long term project viability.
On the bright side, we were truly impressed with the compatibility of .NET Core’s environment on both Windows and Linux operating systems. Both runtimes picked up NuGet dependencies and artifacts, allowing us to easily move computations from the dev box to a more powerful Linux machine, which is loaded more RAM and has an RTX 2080 Ti on board. Deploying this complex solution just worked and, sometimes, we only needed to adjust some runtime data, such as providing a path to a Python executable or registering a shared library.
In our neural network design, we tried to follow the policy network approach described in the AlphaGo paper. With this method, the network receives the encoded board state and predicts the probability of a human player making each of every 150 available moves. The agent filters out the forbidden moves and then takes the option with highest predicted probability.
Unlike Chess or Checkers, Azul has no strict geometric relationship between board parts and tile moves. “Workshops” keep available tiles, while tiles are also moved to a player’s “pyramid” and, at the end of turn one, tile from each completed pyramid row is moved to the player’s “square”, with the remaining ones disposed of. The colours of these pieces are equally important, as the colour of tiles already lying on “pyramids” or “squares” limits your freedom in placing subsequent tiles.
To expose such complex relations, our input data has to encode the complete data about the current state of the common areas and the agent’s user board (as we said earlier, it only cares about its own board, ignoring the opponent’s). We utilised various methods of encoding this information, including:
Depending on the variant, we used between 125 and 800 input variables, which may sound big, but it’s not too much compared to the 7,616 inputs for encoding AlphaZero chess, or over 29,000 for encoding shogi.
Following AlphaZero, we planned to use MCTS via self-playing games to continuously generate new training examples and re-train the neural network using these improving results. Our results, however, landed a little below expectations. We tried fully connected networks, with or without dropout layers, with different numbers of hidden layers and layer sizes, as well as with different activation functions. Our networks, trained initially on a few hundred thousand training examples, reached up to 45% accuracy.
It seems the main problem with Azul is related to symmetry often spotted on board – in many cases, there will be multiple equally good moves. The randomness present in MCTS heuristics can result in different recommendations for the same starting position. And unfortunately, when neural networks will train on such contradictory examples, it won’t gain knowledge that “such moves are equally good” but rather “there is no meaningful relationship here, go away”, which worsens prediction quality. When we switch to TOP3 and TOP5 accuracy metrics, the model answer is presently 65 and 75 percent, respectively.
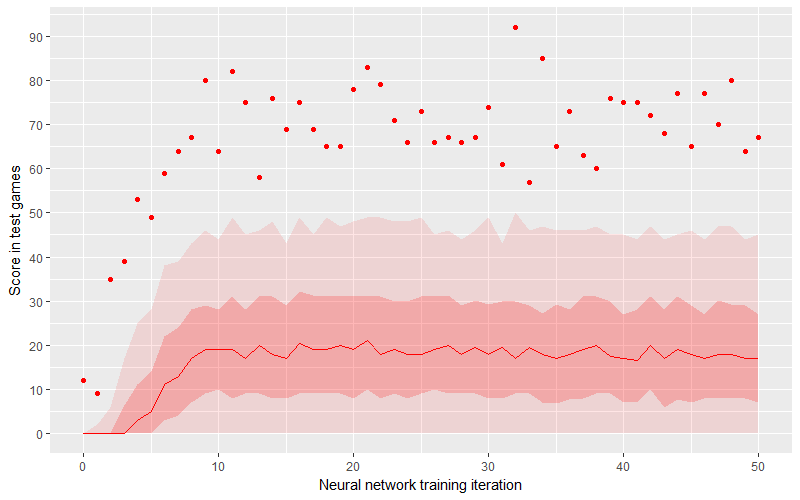
So, how well does the neural network play? Maybe it picks moves as good as exemplary ones, just missing training examples for some reason? Unfortunately, it’s not the case. The average score reaches 20 points, while the middle half of the scores end up between 10 and 30 points. It means such an agent can compete only with the youngest or most inexperienced of players, as even basic training suffices to beat it.
A quick experiment with the xgboost library resulted with similar (~40%) accuracy for tree models and ~30% accuracy for linear models.
Among top three Cloud computation providers, Google Cloud is the most advanced in the area of Machine Learning. After all, Google is still the only company which productised Tensor Processing Units (TPUs), hardware designed specifically for neural network training, faster than any Graphics Processing Unit (GPUs) on the market. We decided to give it a try, using AutoML Tables, advertised as a “fire and forget” solution for both logistics and classification problem. It quickly turned out that we had to prepare a small workaround for our case, as AutoML only allows the classification of up to 40 categories. We therefore prepared two classificators, each outputting different move features, and then combined it’s outputs into one complete prediction set.
As of writing, AutoML Tables remain in the Beta stage. Thanks to a generous promotional offer, we didn’t pay anything to try this service, but regular pricing can be quite expensive – around $20 for one hour of ML training, with extra charges for model deployment and serving predictions.
With this single PoC, we were able to easily burn more than hundred bucks for seven hours of model training, then a few dozen dollars more for models deployment, only to pay an extra $10 for two hours of batch prediction jobs. Keep in mind that all of this was for a dataset with half a million of rows. Boy, it can get expensive so easily. Also, the only training parameter you can modify is the training hours limit.
On a positive note, using AutoML should provide you with a quick predictive baseline score for your data set. You still won’t know which one of “the best of Google’s model zoo” was used in your case, but you will quickly get a production-ready model you can immediately use for both online and batch predictions. In our case, we essentially generated the same results as our hand-crafted neural network – over 60% accuracy for single move features (i.e. the colour of tiles to be taken), about 50% for a combination of two features and a little below 40% accuracy for the complete move prediction. We were initially excited by the much higher score listed in AutoML console, but it turned out it was some other metric under a similar name.
It is worth noting, however, that Azure Cloud also features its own Automated Machine Learning services, while AWS is instead promoting pre-trained services addressing the most common ML use cases – recommendations, forecasting or image analysis. We also tried Uber’s Ludwig, an example of a standalone AutoML package, but it did not bring us any breakthroughs.
Our main R&D goal for this project was to prepare an AI agent able to play Azul. We wanted to try a Neural Network approach, but we also wanted to check how convenient it would be to skip Python and use only a .NET stack for the Machine Learning purposes.
Here are the main outcomes:
In the future, we expect Machine Learning to be commoditised in exactly same way as hardware virtualisation, VPNs, automatic resource scaling or running async client-server apps in a web browser. What was once an interesting novelty, then an expensive technology providing a strong competitive advantage, will eventually become a part of daily business that no one thinks too much about. It will be fun to watch this happening.
Machine Learning is still a developing technology, but the ability to solve the previously unsolvable is more and more accessible with today’s platforms and solutions. As we’ve proven, even open ended problems such as Azul, can be solved with the right know-how and algorithms.


